『融けるデザイン』を読んでまとめた
『融けるデザイン』の骨子
- 情報技術の発展に伴い、ヒトとインターフェイスが融け合う時代になった
- 今までとは異なる新しい設計のための発想とロジックが必要
- 「自己帰属感」という考え方を軸に新しいデザイン=融けるデザインの考え方を整理

- 作者:渡邊恵太
- 出版社/メーカー: ビー・エヌ・エヌ新社
- 発売日: 2015/01/21
- メディア: 単行本(ソフトカバー)
まとめ
体験ベースのものづくりへ
- コンピュータは本来メタメディア=手足の拡張・技術の分化
- e.g. 文書作成、作曲、グラフィック描画などの装置
- が、既存の分化の考え方では説明しにくいものが表れた
- 体験ベースのものづくり
- 現実のメタファ→体験の拡張
- スキュアモーフィズム→フラットデザイン
インターフェイスから体験へ
- インターフェイス=人とモノ・技術の接点
- インタラクション=知覚行為・フィードバック
- e.g. ペン
- ペン先までが身体
- 紙がペン先にフィードバック
- e.g. 車
- 車全体が身体
- 外界(=車体の外)が車にフィードバック
- e.g. ペン
- ユーザーエクスペリエンス=体験
- インタラクションが起こるところで体験が生まれる
自己帰属感とは
- 「道具の透明性」
- ハンマーで釘を打つとき、人はハンマーを意識しないという感覚
- 「自己帰属感」という観点で考える
- 道具が身体の一部だと感じている状態
- 身体性に統合される(人間中心)
- パソコン処理が重くてカーソルがついてこない→「ひっかかる」と感じる
- e.g. マルチダミーカーソル実験
- スクリーン上に大量に配置された偽のカーソルの中から自分が動かしているカーソルを見つける実験
- → 利用者はすぐに見つけ出せるが、観察者はわからない
- 道具が身体の一部だと感じている状態
- 自己帰属率が低い状態
- 連動が乱れている=自己帰属率がシステム側に持っていかれている
- ウェブページの読み込みが遅い→「重い」
- e.g. くすぐり実験
- ある機械を通じて自分で自分をくすぐる→くすぐったくない
- 機械側で300msの遅延をランダムに生じさせる→くすぐったい(!)
- 連動が乱れている=自己帰属率がシステム側に持っていかれている
- 自己感は原因ではなく結果
- 私たちは命令することで手足を動かしている?
- 実は「見る」ことでようやくきちんと動かせている
- 手や足も連動している結果、「私」という輪郭を作っている
- 私たちは命令することで手足を動かしている?
情報を道具に変える
- 「ググるは易く、行うは難し」
- 「インターネットで情報を得る→人間が理解する→人間が問題・課題に適用する」
- 今までの情報はインターネットを介在する
- Encode=実体・現象を記号化してインターネット上にアップロード
- Decode=記号を再現・具現化して具現体に変換
- → 道具自体に情報を紐づける
- 情報がインターネットを介さない
- e.g. smoon
- デジタル化されたレシピ情報に基づき
- スプーンが勝手に計量すべきサイズに変形する
- 計量意識(理解)と計量行為(適用)が不要になる
- 暗黙的な行為を形式知に変える
情報を環境に溶け込ませる
- 情報技術を環境へ融け込ませ、自然に情報を利用
- 時間の使いにくさ
- 時間の長さによる抵抗
- e.g. ドラクエやFFのリリース時、「クリアまで60時間もかかる」ことに批判や抵抗があった
- 利用者の時間をどう奪っているのか、という観点も重要
- 時間の長さによる抵抗
- 非拘束性の設計
- プレユーザー
- ユーザーの「使う」はグラデーション
- デジカメを買って家に置いてある
- 鞄に入れて持ち歩く
- デジカメを構えて写真を撮る
- プレユーザーインターフェイス
- フォトスタンドにもなるデジカメ
- 出かける前に持って行ってほしいことをアピールするインタラクション
- 位置情報に基づき「このあたりは多くの人が写真を撮っている」と通知する
- ユーザーの「使う」はグラデーション
- 制約が生み出す非拘束性
- e.g. Twitterは140文字という制限があった
デザインを現象的に捉える
- 道具-身体システム / 環境-行為システム
- 「モノ」ではなく「肌理と縁」
- 「私たちが周辺を視るということ」を実験してみよう
- 1.少し周辺を視て、体と頭を左右に動かしてみる
- 2.面の重なり合いで起きる縁の発生部分を注意してみる
- 3.縁で起きている肌理の見え隠れは「何の動き」か
- 4.実は「あなたの今の体の動かし方」
- =自己帰属感
- 5.他人ではなくまぎれもなく「私が世界を見ている」という感覚を得る
- → 視ることで、世界と自己を同時に知覚している
- 主観的リアリティと客観的リアリティ
- いくら高画質で解像度の高い映画を見ても、必ずしも映画の中に入り込んだ体験にならない
- 「私は映画館で立体的な映像を見ている」という感想
- なぜなら、人の視覚は実際には2Dで、時間軸によって3D性を捉えている
- いくら高画質で解像度の高い映画を見ても、必ずしも映画の中に入り込んだ体験にならない
- 世界はひとつのOSである
メディア設計からインターフェイスへ
- 情報と物質を分けない
- 体験から考えれば情報と物質の分別はあまり意味がない
- 情報だからといって虚構でない
- 物質だからといって物質的価値があるとは限らない
- 体験から考えれば情報と物質の分別はあまり意味がない
- デザイナーにとっては体験の設計が主となる
- 特定のメディアでのデザイナー(雑誌紙面のデザイナーとか)は徐々にすたれていく
- ライゾマティクス(真鍋大度)はグラフィックでもファッションでもプロダクトでもありうる
- 他にもTakramやチームラボ
- デザイナー・エンジニアリングの垣根から徐々に消えていっている
- 映画・音楽・言葉あらゆるものがメタメディア化していく可能性
- 新しい時代では、「何をやっても新しい」
- すべての問題・物事をインターネットとコンピュータを利用して試し直す価値がある
『Customized Regression Model for Airbnb Dynamic Pricing』を読んでまとめた 【KDD2018】
はじめに
2018年8月19日から23日にかけてロンドンで行われたKDD2018(データマイニングの世界的なカンファレンス)に採択されていた『Customized Regression Model for Airbnb Dynamic Pricing』なる論文を読みました。
Airbnbで実装されている価格推薦モデルについての論文で、
- ビジネス・ユーザー視点を取り入れており、
- 「価格を下げれば予約されていた」と、「もっと価格を上げていてもよかった」というニーズ
- それをうまくモデル化していて、
- 上記を損失関数として定量化
- さらにシンプルな構造で理解しやすい
- ①予約確率の予測→②最適価格の提案→③パーソナライズと、マクロ→ミクロに落ちていく構造
という点において優れたデータサイエンスの応用例であると感じたため、主要な論点を要約しつつ解説に取り組んでみようかと思います。
論文の要旨
最適価格の提案をしたい
まず、Airbnbではホスト側が宿泊料金を自由に設定することができます。
自由は自由でいいのですが、Airbnbに代表されるCtoCのプラットフォームにおいて、需要と供給のよりよいマッチングのために『価格設定』は重要な要素になっていることを考えると、サービス側から最適な価格を提案を出来ると望ましいです。
具体的には、Airbnbの『Smart Pricing』という機能でモデルが算出した最適価格をユーザーが見れるようになっています。ユーザーはモデルが提案している価格を採用してもいいし、参考にして微調整してもいいし、全く利用しないことも出来るようになっていることはポイントになります。

3段階のモデル

①予約確率の予測(分類)
まず、競合の状況や部屋の特長などを鑑みて、とある日付で予約が発生するか否かの確率を計算しています。予約ありを1、予約なしを0にした二値分類タスクになります。 気になるのが使用しているモデルと特徴量ですが、モデルには勾配ブースティング(GBM)、特徴量は以下のような変数を利用しているようです。
- Listing Features
- listing price per night
- room type
- person
- capacity
- the number of bedrooms/bathrooms
- amenities,
- locations
- reviews
- historical occupancy rate
- instant booking enabled
- Temporal Features
- seasonality (the day of the year, day of the week, etc)
- the calendar availability (e.g. the gap between check in and check out)
- distance between today and ds_night
- Supply and demand dynamics
- number of available listings in the neighborhood
- listing views
- searches/contacts rates,
個人的に盲点だなと思ったのが、Temporal Featuresのdistance between ds and ds_nightで、これは計算日から、確率を推定したい日付(当日)までの残り日数のこと。残り日数に余裕があるほど予約確率は高まりますよね。
あと、Supply and demand dynamicsのnumber of available listings in the neighborhood(近隣の宿泊可能な施設数)という変数もなるほどという感じです。個々のアイテムの特徴だけに注目しがちですが、競合の状況も説明変数に入れるとよさげですね。
更なる工夫として、
- マーケットごとにモデルを作り分ける
- ex. Tokyo, California, ...
- 適応的サンプリング(adaptive sampling)
- 宿泊施設激戦区のサンプル数を相対的に増やす
の2つの手法を使うことでパフォーマンスを上げている模様です。(指標はAUC)
たしかにマーケットごとに上記の特徴量の影響が変わったり、 激戦区とそうでない部分では振る舞いに違いが出そうなので、このような差異を上記の手法でうまく処理できていそうですねー。
②最適価格の提案
①のモデルで算出された予約の発生確率を織り込みながら最適な価格を計算していくのですが、 ここで「最適とは何か?」というものを考えておく必要があります。
なぜなら、教科書的な機械学習のモデリングと異なり、今回のタスクでは必ずしも正解ラベルというのが存在しません。 つまり「この価格が最適だった」を示せるような教師データが存在しないということです。 (価格Pで売れたデータがあったとしても、それが最適だったとは言えないですよね?🤔)
そこで彼らは少なくとも最適とはいえない価格とは何か?ということを考えて、 非最適な価格に対して損失関数をあてがうことにします。具体的には以下の2つのパターンです:
実際に設定された価格とモデルが提案した価格
について、
<
だったが、予約が発生した
- モデルの算出した結果が実際に予約された価格
- モデルの算出した結果が実際に予約された価格
- 価格
- 価格
というわけで、上記の条件を使って、損失関数を以下のように定義します。

予約がある場合()と予約がない場合(
)のそれぞれで、「悪くない」価格提案の領域を設定し、そこから離れれば離れるほど「誤差」=「最適ではない」として損失関数で勘定していきます。ヒンジ関数ないしはε-insensitiveのような損失関数の形に似ていますね🤔
次に、以下のように最適価格を推定するモデルを定義します。

肩にいろいろ乗っかってるのでパッと見てやや複雑ですが、ホストが設定した代表価格 *1に対して、以下の2つのスコアを使って補正をかけるイメージです。
- 予約確率
- モデル①で算出
- 需要スコア
- マーケット以下のクラスタごとに計算される需要スコア
- Gaussian Scaleに標準化されている
「なるほど」と思うのが、どうやら需給の上下に対してどのようにマーケットが応対するかは非対称であるようで、 需要スコアが基準値より低い場合とそうでない場合でグラフを「曲げる」パラメータを分けていることです。*2 イメージとしては以下のようになります。

また、最適化をする際にざっくり以下の5つの工夫をしているようです。
- 学習データは
- リスティングごと
- Airbnbでは同じエリア、同じタイプの部屋の中でも価格の分散が大きいため、ひとつひとつを学習データにする
- 直近数週間のデータが中心
- 短期的なトレンドを反映するため
- リスティングごと
- パラメータに制限をかけている
- 大小変化の激しい提案や、差異の小さすぎる提案価格が出ないようにする
- 確率的勾配降下法(Stochastic Gradient Descent)で最適化
- 予約済みの既知データを使ってハイパーパラメータを調整
- 将来時点の宿泊で予約済みのデータを、モデルにマスクした状態で渡す
- → 望ましい試算になるかどうかを検証する
③パーソナライズ
論文では詳しく説明されていなかった(見逃しているかも)ですが、 Airbnbの機能でホスティングの目標(ex. 宿泊頻度を上げたい)や、宿泊価格の最大・最少値を設定できる*3ようになっているので、ユーザーの設定に合わせてモデルの結果をadjustしている模様です。 「これが最適な価格やぞ」とは提案しつつも押し付けはしないわけですね。

モデルの妥当性のチェック
オフライン
定量的には、需要関数が単に価格の関数になるというナイーブな*4モデルをベンチマークに、結果を比較して新しいモデルの効果を示しています。
また、定性的にも、
- 週末に価格が高騰する
- 3月末~4月初旬の桜シーズンに東京の価格が高騰
などといい感じにマーケット毎のシーズナリティを捉えられているようです。 (学習の結果がしっかり定性的な感覚と一致しているのってわりと気持ちよくて、カタルシスがありますよね…)
オンライン
このモデルは既に1年以上Airbnbで実装されていて、モデルのサジェストを適用したホストについて予約数・予約価格共に大きな伸びを見せたそうです(!) 実運用されていて、実績のあるモデルということで精度はお墨付きな感じがあります。
所感
英語力不足と機械学習力不足によって読み下すのに丸1日かかってしまったのですが、データサイエンスのテクニックがかなり凝縮されているように感じました。 当記事では省略した部分や計算式(評価指標など)もいくつかありますので、データサイエンティスト各位はぜひ元論文を読んでみてください|д゚)
KDD 2018 | Customized Regression Model for Airbnb Dynamic Pricing
HackerRankのアルゴリズム厳選20問でコーディング面接を対策する【Pythonコード付き】
HackerRankのCracking the Coding Interview
https://www.hackerrank.com/domains/tutorials/cracking-the-coding-interviewwww.hackerrank.com
HackerRankという、世界中のハッカー(=ソフトウェアエンジニア・機械学習エンジニアなど)が、プログラミング課題を解決するサイトがあります。
そこに「Cracking the Coding Interview」といういかにもコーディング面接対策といった風情のチュートリアルがあるのですが、初心者がプログラミングのためのアルゴリズムを学ぶのに素晴らしい教材だと感じたので紹介します💁♂️
Cracking the Coding Interviewの良さみ
課題の質が高い
まず、かの「Cracking the Coding Interview」(日本では「世界で闘うプログラミング力を鍛える本」)の著者であるGayle Laakmann McDowellが監修しており、課題の質が非常に高いです。難易度設定が適切で、初心者でも考えやすい適度な難易度になっています。
類書などのように「1章からいきなりむずすぎワロタ・・・」となりません🐜たとえば、以下の問題を見てみてください。
入力が1, 1, 3なら出力は3
入力が0, 0, 1, 2, 1なら出力2
など、入力の中で「1つしかない数字」を見つけて出力せよ
ただし「1つしかない数字」以外はすべて2回ずつ表れる
(Bit Manipulation: Lonely Integer)
(※問題文修正 2018/08/02)
この問題は、問題タイトルにもある通り本来はビット演算を使って解くことが想定されているのですが、ハッシュなどを駆使すれば何とか解答することができそうですよね🤔
このように、想定解となるアルゴリズムを知らなくても取り掛かりやすい程度のレベルに調整されています。

世界で闘うプログラミング力を鍛える本 ~コーディング面接189問とその解法~
- 作者:Gayle Laakmann McDowell
- 発売日: 2017/02/27
- メディア: 単行本(ソフトカバー)

Cracking the Coding Interview: 189 Programming Questions and Solutions
- 作者:Mcdowell, Gayle Laakmann
- 発売日: 2015/07/01
- メディア: ペーパーバック
解説の質が高い
さらに、解答は動画付きで丁寧に解説されていて、コードとにらめっこしていてもわからないようなアルゴリズムのかんどころを視覚的に説明してくれています。
アルゴリズムは、言葉で聞くと難しく感じてもビジュアルで理解するとすんなりわかることも多いため、動画が付いてくるのは非常にありがたいです。
以下は上記の問題の解説動画です。ご覧頂ければどれだけ詳しく解説してくれるかわかるかもしれません。
ちなみに、ハッシュを使った解答もビット演算を使った解答も解説してくれていて、「なるほど、そう解けば良かったのか💡」と理解が丁寧に促されます。
問題が厳選されている
問題が20問に厳選されていて、短期集中的に取り組みやすいです。私は週末で一気に終わらせました。
書店で分厚いアルゴリズム本を買ってきて「アルゴリズムおおすぎワロタ・・・」となった経験がある方には特におすすめです😇
具体的には、以下の全20題に厳選されています。
データ構造
テクニックおよび概念
単純に解いていて楽しい問題も多いためモチベーション維持にもGoodでした。
議論が闊達に行われている
問題ごとに設定されているディスカッションタブというのを開くと、各言語での実装例や、他の人の解法・考え方を学ぶことができます。
他サイトと比べてもわりと議論がアクティブなため、どうしてもわからないことがある場合があっても質問すれば回答が返ってくることが多いです。私は質問を投稿して半日以内に返信が来ました🙏
おわりに+Python3での実装例
アルゴリズムはプログラミングに登場するさまざまな概念の基礎になっていることが多いので、このような教材で集中的に学んでおくのがよいと感じます。
私はデータアナリストでふだんPythonを使って分析を行うことが多いため、Python3で挑戦してみました。GitHubにあげておいたので、Pythonでトライしてみようという方は参考にしてみてください|д゚)
テレビCMの残存効果をAd Stock(アドストック)で計算してみる【R & Pythonコード付き】

テレビCMの効果測定
昨今の広告市場を席捲しているデジタル広告市場においては、「効果測定」をしろと言われたば、 CVR(コンバージョン率)やCPA(獲得単価)など、極めて精緻で細やかな指標を用いてレポートすることができる。 そのため、広告をどれだけ出稿するかの意思決定を正確なデータに基づいて行え、大変使い勝手がよい。
しかしながら、このようにデータが整備されているデジタル広告と異なり、 新聞、雑誌、ラジオ、テレビなど古来からのメディアの効果測定はデータ分析にひと工夫が必要だ。
今回は、最もポピュラーに使われている「テレビCM」の効果測定を例にして考えてみよう。
例:テレビCMの効果測定
たとえば、以下のように「テレビCMとその視聴率」と「売上」の時系列データがあったとして、 「効果測定」をしたい状況を考えよう。(※架空のデータ)
| 日付(週) | 視聴率 | 売上 |
|---|---|---|
| 2018年6月11日 | 0% | 30万 |
| 2018年6月18日 | 10% | 80万 |
| 2018年6月25日 | 15% | 60万 |
| 2018年7月2日 | 8% | 120万 |
| 2018年7月9日 | 10% | 140万 |
どのように分析すればいいだろうか?
まず考えたいのは、 「視聴率が高い日に売上もあがっているのではないか」ということだ。
――しかしながら、よく見てみると視聴率が最も高い15%の日に、売上が2番目に低い60万となっているため、 この仮説の蓋然性は低いと考えられる。
グラフにしても以下の通りである。 「視聴率が高い日に売上もあがっている」と読み取るのは難しいだろう。

このようなデータは頻繁に出くわすのだが、 実はひとつの理由にテレビCMの効果には時間差があることがある。
たしかに、ゲームアプリのCMを見て、すぐにウェブ検索をしてアプリをダウンロードすることもあるだろうが、 化粧品のCMを見て、翌日または数日後にドラッグストアで買って帰る場合や、 高級な家電製品のCMを見て、ボーナスが出た翌月に店頭で購入する場合など、 効果のあらわれ方には時間差があることは想像に難くないだろう。
どうやって正しく効果測定するか?
広告の残存効果(アドストック)
このような効果の測定には広告の残存効果をモデル化したアドストックという指標を導入する。 英語ではAd Stock、Carry Over Effect、あるいはDecay Effectなどという表現をされることもある。

上図のように、広告を打った初週だけでなく、 翌週、翌々週以降も効果が残存しているという設定でモデルを定式化する。
定式化
Def: Simon Broadbent's Adstock Advertising adstock - Wikipedia
時点tでの残存効果(アドストック)を以下のように定義する。
ただし、
: 時点tでのAdStock
: 時点tでの広告指標(たとえば視聴率)
: 忘却率(減衰率・残存率)※
- どれくらいの割合で減衰していくかを表す定数
- 0から1の間の数値を取る
※エビングハウスの忘却曲線のように、「消費者の脳内に広告の効果が留まっている」という考え方をして、「忘却率」と呼ぶ場合がある。
具体例でみる
「むむむ数式だけだとイメージが湧かないゾイ」という方には、 実際にアドストックを計算した例を用意したのでご覧いただきたい。数値は上記の例をそのまま使っている。
忘却率を仮に0.80と仮定すると、以下のようになる。
| 日付(週) | 視聴率 | アドストック | 売上 |
|---|---|---|---|
| 2018年6月11日 | 0% | 0% | 30万 |
| 2018年6月18日 | 10% | 10% | 80万 |
| 2018年6月25日 | 15% | 23% | 60万 |
| 2018年7月2日 | 8% | 26% | 120万 |
| 2018年7月9日 | 10% | 31% | 140万 |
Excelで計算した場合の数式は、以下の通りである。 ぜひ、上記のモデルの数式と見比べながら確認してみて欲しい。

グラフにしてみると、ただの視聴率(GRP)を使っていたときと比べて、 広告の効果がはっきりとわかる形になっていることがわかるだろう。

忘却率をどうやって決めるか
さきほどは忘却率を0.80と仮に決めていたが、実際の現場ではどのように決めるのが妥当だろうか。 以下にふたつの方法を提案する。
1. 忘却率ごとに相関を出して最適化する(定量的)
ひとつは、広告効果を最も適切に説明するようなパラメータを機械的に選びとる方法である。
忘却率が0.01のとき、0.02のとき、・・・、0.98のとき、0.99のとき、と忘却率を100通り試して、 アドストックと広告効果の相関が最も高くなるようなパラメータを選びとればよい。
PythonやRで計算してもよいし、100通り程度ならExcelでガガっと計算させるのいいだろう。今回はPythonでスクリプトを書いて最適なパラメータを見つけ出してみよう。
本記事の下部に掲載したPythonスクリプトを読み込んだ上で、adstock_optimize(grp, sales)の形で実行すれば以下のような結果になる。

グラフより、忘却率=0.78で相関係数が最大値をとるようなので、 忘却率=0.80としていた上記の例は、定量的に考えても筋が悪くはなさそうだ。
2. 商材・メディア・クリエイティブなどに合わせて決める(定性的)
ふたつめは、商材・メディア・クリエイティブなどに合わせて経験的に設定する方法である。
前段で触れたように、商材やクリエイティブの訴求方法によって広告の効果の表れ方が変わるのは 明らかだが、メディアによっても平均的な忘却率が存在すると考えられている。
実際にメディアに携わっている人などからヒアリングしたり、 分析の経験豊富な人から経験的な数字を教えてもらうなどして、忘却率を設定しよう。
半減期
なお、忘却率を表現する指標として「半減期」というものがあり、
効果の半分が無くなってしまう時点のことを表し、 概ね「広告効果はこれだけ持続しますよ」というものを表現している。
概ね、以下のようなものだと言われている。
- テレビ:2-6週間
- ラジオ:1-5週間
- 新聞:2-3週間
- 雑誌:4-8週間
- オンライン(認知):2-4週間
- Yahooのトップページなどのように、認知目的の広告
- オンライン(行動):1-2週間
- 刈り取り型の広告、リターゲティング広告など
(引用元:How Long Does Your Ad Have an Impact?(筆者訳))
忘却率をヒューリスティック(経験的・直観的)に定めたあとは、 上記のようなベースラインと見比べて過度に大きく・小さくなっていないか確認しておくとよいだろう。
さいごに
今回は、以下の3つのキーワードを扱った。
- アドストック
- 残存効果・Ad Stock・Carry-Over Effect・Decay Effect などとも言う
- 忘却率
- 半減期
広告の効果測定にはさまざまなモデルが提案されていて、日々論文も書かれているため なかなか何を使えばいいか難しいのだが、主要なモデルのひとつとしてぜひ理解しておいてほしい。
付録:Ad Stockを最適化するスクリプト
Python
Calculate the optimal Ad Stock
R
「動物は何を報酬として行動しているのか」が逆強化学習で明らかになる

一般に強化学習というと、
- どの状況でどれくらい報酬を得られるのかはあらかじめ決められており、試⾏錯誤によって得られる報酬を最⼤化する⾏動戦略を⾒つけ出す
- 動物はすでに最適な⾏動戦略を獲得しているとして、計測された⾏動時系列データから未知の報酬を推定する
モデルである。
素人ながらざっくり解釈すると、
- 線虫の行動戦略は逆強化学習のモデルで説明可能
- 知覚(状態のインプット)
- 行動(確率的)
- 報酬
というのがfindingsということになりそうだ。
私的には、付随的に明らかになっている
- 育った環境で行動戦略が確定する
- 初期値に依存
ということが面白いと感じた。
果たして行動戦略が確定する(※)までどれくらいの期間を要するのか気になるが、 ヒトの教育方法・成長過程は強化学習どれだけモデル化できるのか気になるところである。
(※)モデルの係数が何らかの解に収束する
Excelの重回帰分析でタイタニック号乗客の生存予測をやってみよう

はじめに
- データサイエンスに興味がある
- Excelなら使える
- ピボットテーブルなら聞いたことあるぞ!
という方々向けに、Excelの基本的な機能と関数のみを使って、データ分析(重回帰分析)を行う流れを説明していきたいと思います。
みなさまが本格的なデータサイエンスの勉強を始める前の足掛かりとなれば幸いです。
分析
0. 目的
1912年の北大西洋にて、当時最大の旅客船である「タイタニック号」が沈没した事件はみなさまご存知でしょう。 実は、乗客全員が死亡したわけではなく、何とか生存することができた人たちもいました。
それでは、どのような人たちが生き残ったのでしょうか?
- 階級の高い乗客が優先的に助けられたのでは?
- 体力がありそうなので若い男性が生き残ったのでは?
- ...
などなど、いろいろ考えられますよね。
今回は、このような仮説が本当か?ということをデータ分析で検証しながら、 最終的に乗客の情報をインプットすると、その乗客が生存したか否かをアウトプットしてくれる関数を作成することを目指していきましょう。
1. 準備
以下の手順に従って「タイタニック号の乗客データ」をダウンロードしましょう。
- Kaggleに登録
- https://www.kaggle.com/
- 注:Kaggleとはデータサイエンティストが腕を競い合うSNSのようなものです
- タイタニック号の乗客データ(
train.csvとtest.csv)をダウンロード
エクセルでtrain.csvを開くと、以下のようなデータが見れるはずです。
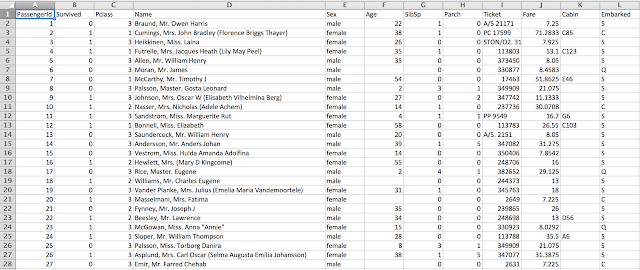
2. データを概観する
2-1. 変数の意味を調べる
まずは、それぞれの列(=変数)が何を意味しているのかを確認しましょう。 Kaggleに記載されているデータセットの情報を見ると、以下の説明があります。
- PassengerID
- 乗客の番号
- Survived
- 生存結果
- 1 = 生存
- 0 = 死亡
- 生存結果
- Pclass
- 乗客の階級
- 1 = 1st
- 2 = 2nd
- 3 = 3rd
- 乗客の階級
- Name
- 乗客の名前
- Sex
- 性別
- Age
- 年齢
- SibSp
- 兄弟、配偶者の数
- Parch
- 両親、子供の数
- Ticket
- チケット番号
- Fare
- 乗船料金
- Cabin
- 部屋番号
- Embarked
年齢や性別だけでなく、兄弟の数や、乗船した港もわかるようですね。 果たしてこれらの情報は生存したかどうかに関係があるのでしょうか?
2-2. ピボットテーブルをつくる
それぞれの変数が生存したかどうかに関係があるかを確認するためには、ピボットテーブルを使います。以下のいずれかの方法でピボットテーブルを作ってみてください。できない場合はこちら
▼ピボットテーブルの作り方
- [挿入]から[ピボットテーブル]をクリックして、データの範囲を選択
- データの範囲全体を選択して、
Alt->N->VでもOK
- データの範囲全体を選択して、
2-2-1. 軸を決めて比較する
ピボットテーブルをつくると、特定の軸を決めて比較することができます。 たとえば、性別ごとや乗客の階級ごとの生存率を見ることができます。
ここは全くデタラメにやっても構いませんが、0. 目的でも言及したように「階級の高い乗客が助かったのでは?」「体力がありそうなので男性が生き残ったのでは?」などと、仮説を持ちながら検証していくと質の高い分析になるでしょう。
まずは、乗客の階級ごとの生存率を見てみましょう。 果たして階級が高い乗客の方が生存率が高いのでしょうか?
▼ピボットテーブルで乗客の階級ごとの生存率を見る
- ROWS(行)に
Pclassを入れる - VALUES(値)に
Sum of Survived(=生存者数)とCount of PassengerId(=乗客数)を入れる - 生存率
= 生存者数/乗客数を計算する
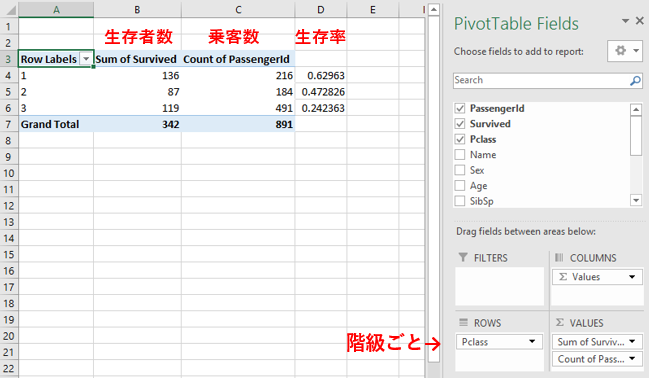
一等級の生存率は63%ですが、二等級は47%、三等級は24%と下がっていっています。 これより階級の高い乗客は生存率が高いことがわかり、仮説は立証されました。
同様にして、性別ごとの生存率を見てみましょう。 果たして男性のほうが生存率が高いのでしょうか?
ROWS(行)にPclassではなくSexを入れるだけですね。

男性の生存率が19%で、女性の生存率が74%。 以下のようにグラフにしてみると差が一目瞭然です。
▼ピボットテーブルからグラフをつくる
- ピボットテーブルの適当な場所をクリックした状態で、[挿入]から[おすすめのグラフ]をクリック
- または
Alt->N->RでもOK
- または

つまり、女性の生存率が非常に高いことが分かり、仮説が棄却されました。
AgeやSibSp(兄弟、配偶者の数)、Parch(両親、子供の数)など他の変数とSurvivedの関係もぜひ手作業で確認してみてください◎
コラム:なぜ女性の生存率が高いのか?
実は、当時日本人としてただ一人の乗客であった細野正文氏によるタイタニック号事故生き残りの手記に、以下のような記述があります。
... 船客はさすがに一人として叫ぶ者はなく、皆落ち着いていたことは感心すべきことだと思った。ボートには婦人たちを優先的に乗せた。その数が多かったため、右舷のボート4隻は婦人だけで満員になった。その間、男子も乗ろうと焦る者も多数いたが、船員は拒んで短銃を向けた。この時船は45度に傾きつつあった。
乗客はパニック的状況の中でも焦らず、徹底して女性を優先的に救助していたようですね。
2-2-2. 欠損値をチェック
次に、「空欄になっていてデータが入っていないセル」に注目しましょう。 データ分析用語では、欠損値と呼びます。
パッと見ると、AgeやCabinのデータが歯抜けになっていますが、 欠損値がどれくらいの割合を占めているかピボットテーブルを使って確認しておきましょう。
ピボットテーブルのROWS(行)にAgeを入れてみてください。

すると、空欄になっているデータが177個あることがわかりました。 全体のデータが891個なので、2割ほどのデータが欠損しているようです。
2-3. 相関係数を計算する
「2つの変数がどれくらい関係があるか」を-1から1で表した、相関係数と呼ばれる指標があります。
この指標が1に近いほど、「片方の変数が大きいとき、もう片方も大きくなる」傾向にあり、これを正の相関と呼びます。 逆に、-1に近いほど、「片方の変数が大きいとき、もう片方は小さくなる」傾向にあり、負の相関と呼びます。
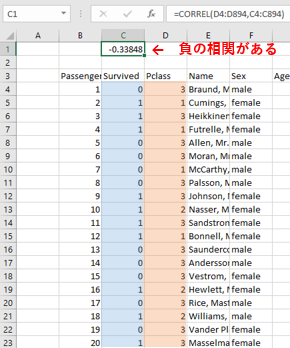
たとえば、2-2-1. 軸を決めて比較する で検証したように、「乗客の階級が1に近い(小さい)とき、生存率が高い(大きい)」ことがわかっていますので、乗客の階級と生存率は負の相関になっているはずです。確認してみましょう。
▼相関係数を計算する
=CORREL(変数の範囲, 変数の範囲)で、Survivedのデータの範囲とPclassのデータの範囲を指定すればOK
3. データを整形する
ここからは本格的にモデルを組むため、データをモデルが読み込みやすい形に整形していきましょう。
3-1. 使わない変数を削除する
まずは、必要のない変数を削除します。
ここでは、分析のやりにくそうなTicketとNameを分析に使わないことにして、削除してしまいます。
逆に、2. データを概観する で検証したようにSexやPclassは生存率に大きくかかわる変数ですので、必ず残しましょう。
3-2. ダミー変数をつくる
さて、分析を行うために、SexやPclassなど、数字ではないデータをダミー変数に変換する必要があります。
ダミー変数とは、数字ではないデータを「0」か「1」で表すことです。 以下の要領で実際に変換してみましょう。
▼Sexをダミー変数に変換する
- 男性であること1か0で表す変数
Maleの列を追加する =IF(参照セル="male", 1, 0)- すべての行が埋まるように縦にコピーする

このようにすると、変数Maleが1のとき男性、0のときは女性を意味します。
▼Embarked(乗船した港)をダミー変数に変換する
- 乗船した港がサウサンプトンであること1か0で表す変数
Sの列を追加する =IF(参照セル="S", 1, 0)- すべての行が埋まるように縦にコピーする
- 同様に、乗船した港がシェルブールであることを1か0で表す変数
Cの列を追加する =IF(参照セル="C", 1, 0)- すべての行が埋まるように縦にコピー

コラム:乗船した港がクイーンズランドであることを示す変数は要らないの?
もちろん作ることができます。=IF(参照セル="Q", 1, 0)とすればいいですね。
しかしながら、SとCがともに0のとき、それはQになりますよね?
Sexの変数に対して、変数Maleしか作らなかったのと同様にして、あえて作っていません。

次に、Cabin(部屋番号)のデータもダミー変数にしていきます。
部屋番号の種類は膨大な数があるため、各部屋番号に対してひとつひとつダミー変数を作っていくと埒があきません・・・。
"Titanic Cabin"でGoogle 画像検索をかけてみると以下のような画像が出てきます。

客室の階数によってAからGまでラベルが降られているようですね! Aに近ければ近いほど、救命ボートに近いため生存確率が上がりそうだな、などということを考えつつ、部屋番号の頭に付いている英字がCのとき、Eのとき、Gのとき、とダミー変数を作っていくことにします。
▼Cabinをダミー変数に変換する
- Cabinの頭の英字がCであること1か0で表す変数
CabinCの列を追加する =COUNTIF(参照セル, "C"&"*")同様の作業をA~Fで行う
- ふつうの
=IF()ではワイルドカードは使えないので=COUNTIF()を使う

3-3. データを補完する
最後に、2-2-2.で見た欠損値を何とかして補完していきます。 以下のような方法が考えられます。
統計量を使って補完
Ageの欠損値を「平均値」や「中央値」で代替
他の変数のデータを使って補完
- たとえば、
CabinとPclassの相関をチェック- もし相関があれば、Pclassが1に近い人はCabinもAに近いようにする
今回は簡単のため、Ageの欠損値を平均値=AVERAGE()で埋めて、Cabinの欠損値はそのままにしておきましょう。
4. モデルをつくる
4-1. 重回帰分析を行う
重回帰分析とは、乗客にかんする情報が、乗客の生存可能性にどれくらい寄与しているかを分析する手法のひとつです。このとき、乗客にかんする情報のことを説明変数と呼び、乗客の可能性のことを目的変数と呼びます。
式に表すと、以下のような形になります。(回帰式)

たとえば... アイスクリームの売り上げ数 = 30 * 気温 + -5 * 値段 + 100 というような形で、気温や値段などの説明変数(の線形和)で、目的変数を表現します。
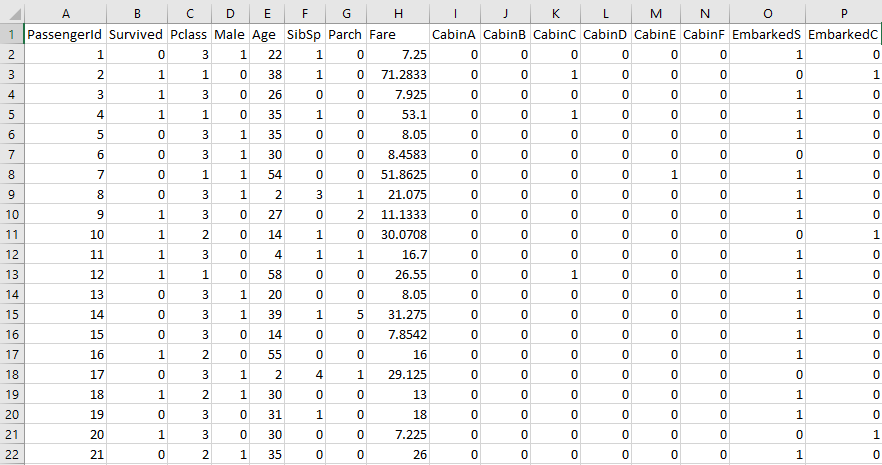
もし無事にデータ整形が完了していれば、データは以下のように数字だけになっているはずですので、これに対して重回帰分析を行っていきましょう。
▼重回帰分析を行う
- [ファイル] タブをクリックし、[オプション] をクリックして、[アドイン] カテゴリをクリック
- [管理] ボックスの一覧の [Excel アドイン] をクリックし、[設定] をクリックします
- [アドイン] ボックスで、[分析ツール] チェック ボックスをオンにし、[OK] をクリック
- シートに戻り、[データ]→[データ分析]→[重回帰分析]とクリック

- [入力Y範囲]にSurvivedの列の範囲を選択(目的変数)
- [入力X範囲]にそれ以外の変数の範囲を選択(説明変数)
- [ラベル]にチェックを入れておく
うまくいけば、以下のように重回帰分析の結果が得られるはずです。

Coefficients(係数)の部分に書かれている数字が、 以下の式でいうところのa_1, a_2, ... , a_n, bに相当しています。
すなわち、回帰式の係数が分かったので、乗客の情報を入れればその人が生存するかどうかがわかるモデルが完成しました!
4-2. 推定する
さて、得られたモデルを使って、乗客の情報から生存予測をしてみましょう。
まずは、test.csvからテストデータを開き、分析に使ったデータと同じ形式に変換してください。
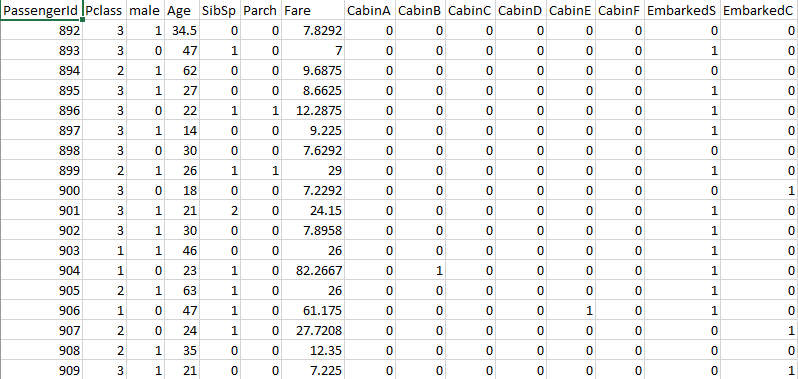
Regression, Survivedという2つの列を追加したのち、以下の手順で推定を行っていきます。
▼作ったモデルを使って生存予測をする
- 回帰式の係数をコピーし、適当な場所に
Ctrl + Alt + Vで縦横を転置して貼り付け SUMPRODUCT(ベクトル, ベクトル)を使って回帰式を計算- 閾値を設定して
=IF(得られた値 > 閾値, 1, 0)を使って1か0に変換する
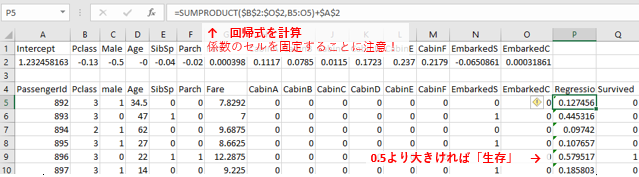
コラム:閾値はどういう意味?
重回帰分析は、アイスクリームの売り上げなどのようにあくまでも「実数」を返すモデルです。 しかし、今回は生存したかしていないかを「生存」か「死亡」で表現しなければいけないため、
- モデルがはじき出した数字が1に近ければ「生存」つまり1
- 0に近ければ「死亡」つまり0
という形で変換を施しています。
4-3. 検証する
最後に、モデルで得られた生存予測を検証してみます。 まずは、テストデータと予測結果いをPassengerID, Survivedだけ残してcsvで出力してください。
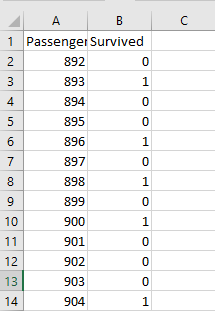
それをSubmit FormからKaggleに提出すればOKです

結果を見ると、Excelで作ったモデルは正答率76%を記録しました
あとがき
いかがでしたでしょうか?
Excelの関数・機能のみを使ってデータ分析を行うイメージが付きましたでしょうか?
Excelは、
- そんなに重くないデータを概観するにはとてもよい
- ピボットテーブルやグラフなども使いやすい
- 重回帰分析もワンクリックでできる
- 実はすべての変数の相関係数を一気に見ることもできる
- データ分析の機能をオンにして、「相関」を使えばOK
などなど、データサイエンスをはじめるに当たって基礎的な機能はしっかり持っていますので、 特に初めたてのころは、Excelだけを使ってある程度の分析を行っていけるかと思います!
『UXデザイン入門』に学ぶ、デザイン調査のパターンとポイントまとめ

- 作者: 川西裕幸,潮田浩,栗山進
- 出版社/メーカー: 日経BP社
- 発売日: 2012/01/26
- メディア: 単行本
- 購入: 5人 クリック: 246回
- この商品を含むブログ (4件) を見る
デザイン調査
- 「ユーザーについて知る」こと
- 具体的には、「ユーザー」そのものと「ツールの利用状況・目的」の理解のこと。
モチベーション
- どんなユーザーが(who)
- どんな状況で(where, when)
- どんな目的を達成しようとして(what)
- (もしあれば)どのようにツールを使っているのか(how)
に加えてさらに、
- なぜか(why)
を引き出していく。
ポイントは、現行のUIの問題点や改善点の抽出ではなく、 ユーザーの利用状況や目的を理解し、根底のニーズ(why)を理解していくこと。
ターゲット
まず、調査対象のセグメントを設定する必要がある。
ユーザーが特定の領域に限られる場合
たとえば、企業用の会議室予約ソフト。
- 既に使ってくれている企業
- 似た環境で既存のシステムを使っている人
など範囲は絞られるので、具体的な組織などにアクセスできればOK。
ユーザーが広範囲に及ぶ可能性がある場合
たとえば、オンライントレードに興味がある人向けのウェブサイト。
ユーザーの設定が抽象的の上、かなり相当数の想定ユーザーがいる。 この場合はユーザーとしての条件を設定し、その条件を満たす代表サンプルをターゲットに設定する。
具体的な手法としては、
- 不特定多数に上記の条件に関する事前アンケートを行い、ふるい(スクリーニング)にかける
- 条件を満たしたユーザーのみを対象に本アンケート・インタビューを行う
などが考えられる。
デザイン調査のパターン
Contextual Inquiry
- 観察
- 目の前でツールを使っている様子を見ながら、
- インタビュー
- どのような目的で、どのように利用してるかなど質問
をする方式。エスノグラフィー。 ニーズを探し出すのに最も情報が多いと考えられるが、コストが高い。
ポイント
- 師弟関係のイメージで、教えを請う形でインタビューを行うこと。
ユーザーインタビュー
- ユーザーと直接対話する。
- 対面でも、電話やビデオ通話でも可。
複数人で行うグループインタビューの形では議論の活性化(グループダイナミクス効果)が期待でき、 1:1のインタビュ―で聞けなかった意見が聞ける可能性もある。
ポイント
- 信頼関係(ラポール)を築くため、世間話や雑談等から始めること。
- 長丁場にしない。集中力が切れてしまう。
※UXデザイン入門の筆者の経験では、ユーザーの根底に潜むニーズの理解には、広くインタビューするグループインタビューよりも、深くインタビューをする1:1のインタビューの方が有用なデータが得られることが多い、らしい。
観察調査
- ユーザーがどのようにツールを使っているか観察する。
- ただし、こちらから働きかけをしない。
eg)「電子案内板」の設計などはフィールドワークで観察。
ユーザビリティテスト
- ユーザーのタスクを課し、そのタスクを完遂するまでの振る舞いを観察する。
UIの設計にフォーカスした改善・改修のためのユーザビリティテストとは異なり、 あくまでも振る舞いから潜在的なニーズを明らかにすることがポイント。
サーベイ
- アンケートを作り答えてもらう
このリストの中では最も「定量調査」に近い。
日記調査
- ユーザーに日記やフォトエッセイを書いてもらう。
中長期的な利用が見込まれるデザインに有用。
eg) 不動産販売サイト
マンションの購入を検討しているユーザーがどのようなメディアを利用して、どのようなWebサイトをどのような順番で利用して、最終的に何が決め手になって購入に至ったか、などをユーザーの記憶が新しいうちに記憶してもらうことで、精度の高い情報が得られる。
プロセス
計画
- 調査事項を明確にする
- 手法を決定する
準備
- 対象ユーザーのリクルーティング
- 振る舞いが異なりそうなセグメントがわかっている場合、事前調査(スクリーニング)などを行いそれぞれのセグメントから数人ずつ抽出できるとよい。
実施
- 現地での記録
- インタビューの実施
- ディブリーフィング(振り返り)